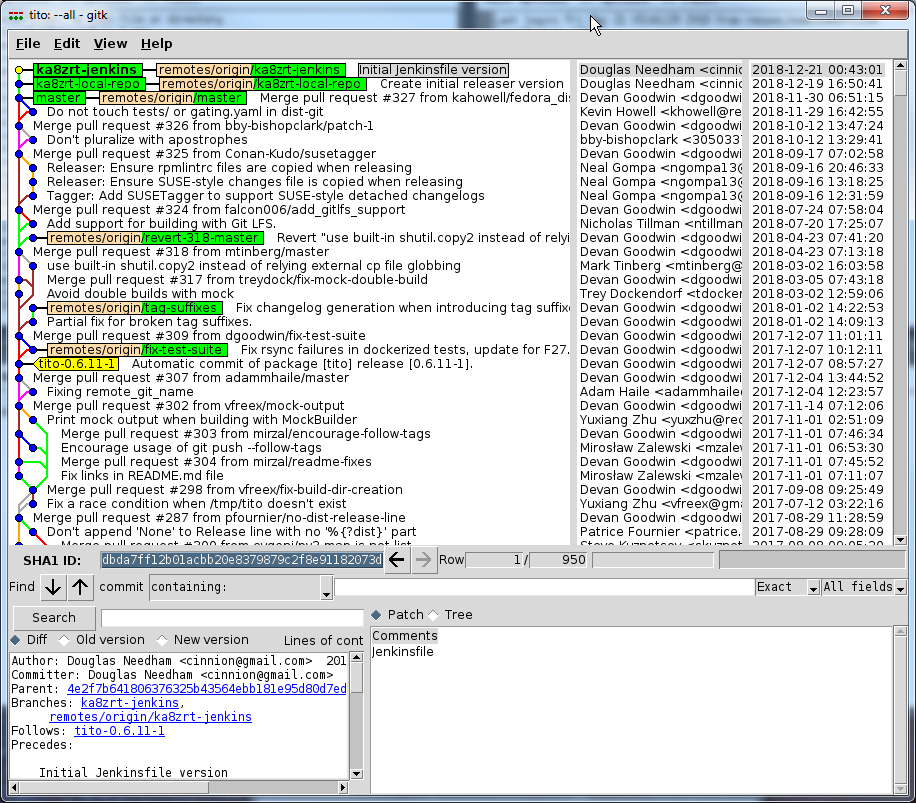
Granddaddy built houses for decades, and while I don’t think I heard the adage from him, I learned all about using the right tool for the job growing up, between what I learned from Mom, and from what I learned through personal experience. For example, it is quite obvious that you don’t use screwdrivers for driving nails into boards, but then you are faced with all the different hammers, all slightly different, for driving a nail… and we have not even considered the size of the nail. And sometimes, even with all those choices, we are left unaware that there is an even better tool out there which is as better suited to the job as the worst hammer is over the screwdriver. The same is true in building software and installing it on your computer.
Some history
Now, over the years, I have dealt with this in so many ways. In what might as well have been the Dark Ages, we would take files off of magnetic tape, do what might as well have been incantations, and in the end, have the software running on our system… hopefully… It did not always work out that way. Missing a compiler flag, having the wrong library, or the wrong version… so much could go wrong. Improvements were inevitable, especially when you had some of the brightest minds using something which could do something over and over, far faster than we could, and make far fewer mistakes, other than reproducing the garbage we sometimes put into the process. And for each machine on which we wanted that software, odds were, we were repeating that process on each and every machine. So we started using shell scripts, makefiles, and other items… but there was even more lacking. Did we have a given package installed, and was it the right version?? And so we made package managers, to the point where today they are coming out our ears (or elsewhere). And each platform, both hardware and OS, seem to come with their own, and then some. I have used proprietary package managers on OSes like SunOS/Solaris, AIX, and HP/UX , more open managers such as NetBSD’s pkgsrc, and these days, mostly use Red Hat’s RPM with tools such as Yum. But then, certain languages such as Perl, PHP and Python (which I have used since their earliest days) are generally platform independent once you have the core language engine (executable/interpreter) installed, and they have their own internal packaging, and centralized repositories. Perl’s cpan command, PHP’s pear, pecl and composer, and Python’s pip all come into play here, but do not integrate outwardly with the OS package manager. And so, we are at times still forced to some extent to re-live the dark ages. But that is a different topic and a different post (or series thereof).
RPMs… how do we get there??
Every package manager works to reduce the headaches of what OS version are we using, what CPU architecture are we using, and what else do we need to have installed to run it. But depending on some of those details, we may find what comes off the shelf to be frustratingly lacking. Henry Ford said one morning “Any customer can have a car painted any colour that he wants so long as it is black.”. And this was definitely something old Ma Bell/Western Electric took to heart. The model 302 telephone was almost exclusively black… though since the phone was owned by the phone company (it was a part of your monthly phone bill), they did realize that there was some extra profit if they painted them a few different colors. But even in the 1960’s, a decade after the introduction of the model 500 with its 36 different colors, unless you were were a company with a good reason, odds were that your phone was black. It really was not until the 80s that we got the real choice of colors. And the same is true of software. If you have a LTS (long-term support) version of an operating system, you could go years without an update you wanted, because for support organizations, often times it is considered to be better to patch problems and not introduce newer problems with newer version, than it is to just move to the newer version. Or perhaps you find yourself wanting a particular option enabled, and being like an individual who wanted a white Model T. But then, one of the great things about Open Source is you can get around things like that, if you opt to do so. But to do so, we need to know what our tools are.
At the core of the RPM toolbox, we have tools such as rpmbuild. This is far better than the earlier tools, but can still leave you with an involved process, even with newer tools like yum-builddep to help. And like the old pkgsrc days in NetBSD, you either find yourself with everything and its brother installed on your system, or having to use tricks like chroot or today’s containers to make it so that you can go back to a “stable” starting point. You can almost think of this as mowing your lawn with one of these…

It is ok for occasional one offs or simple things, but soon, you find yourself trying to do things a better way.
And what this still leave you with is how to get the package installed onto your system. At the end of doing your rpmbuild, you have a RPM file which may need to go onto one host, a dozen hosts, or maybe thousands, starting from when you have that installable RPM. And while you might be willing to copy that file to a few hosts and run the command to install it (which gets simpler with things like Ansible playbooks/roles), it makes far more sense to use the tools used for distributing the OS and its updates, which brings in the createrepo tool.
When doing things by hand just does not cut it…

Yes, you saw what I did there… Just like when your yard is too big, or you have to do it far too often, you find yourself wanting to make things easier for yourself, and justifiably so. But at the same time, how many of those attempts just get us something we will think is great a year or two down the road, and how many will we end up thinking “WTF was I thinking??!!”, given how many of them can turn out to be real Frankenstein’s monsters. (I actually remember seeing a video of such a reel-style lawn mower, but could not find a video/picture, which seemed like 1/2 go-cart, 1/2 dragster, 1/2 lawn mower and 150% monster straight out of a horror movie or Mythbusters…)
Yes, sometimes, we get things right. I have a few such tools sitting in my old toolbox, which were I to start using a NetBSD distro today, would just take a few tweaks, and after some hours of compiling, I would find myself with a running configuration, complete with familiar editors and all. But at other times, we find ourselves at the other end of a totally different mower. After all, just because we find ourselves able to graft wings onto a male bovine does not mean that it will be able to fly. It may slice, it may dice, it may julianne… but it will also quickly take your finger off. And so, let us first take a simplified look at the core process we are doing here…

When you look at this, it looks simple, but realize that the chain of rpmbuild through publish is repeated for each combination of (distribution, version, architecture), and the install is replicated for each machine. And this last step is what drove the whole packaging things as RPMs, Python “eggs” or other forms clear back in beginning.
So how bad is this? Well, for me, it potentially means 8 separate times through the valley of builds, to say nothing of the deployment, which for me is almost two dozen machines (that number may vary, as I can spin up virtual machines in relatively short order, or destroy ones used for testing in moments. And depending on what I am doing, maybe I have to rebuild a package from scratch for every one of those distro/architecture combinations. And let me say right now, there are things I would far rather do than go through that process multiple times. And when you add in setting up the build environments on top of that… ACK!
Tools to the rescue…

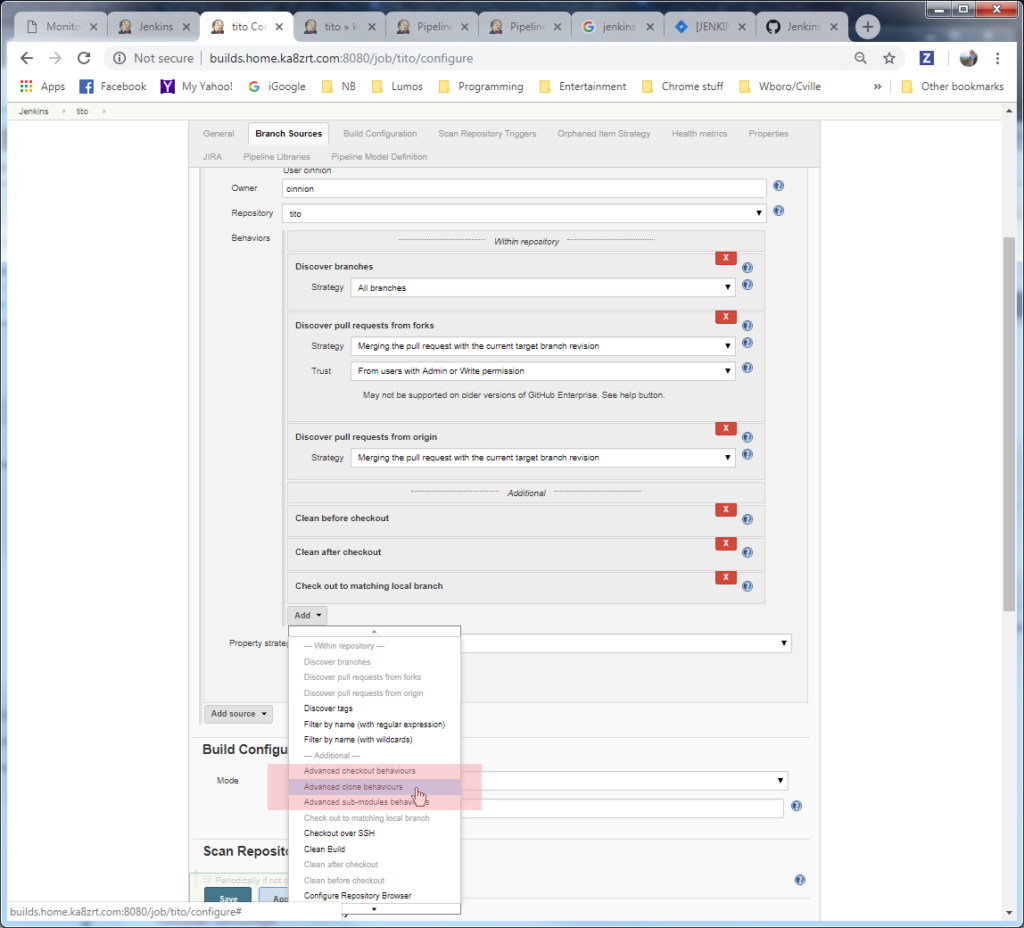
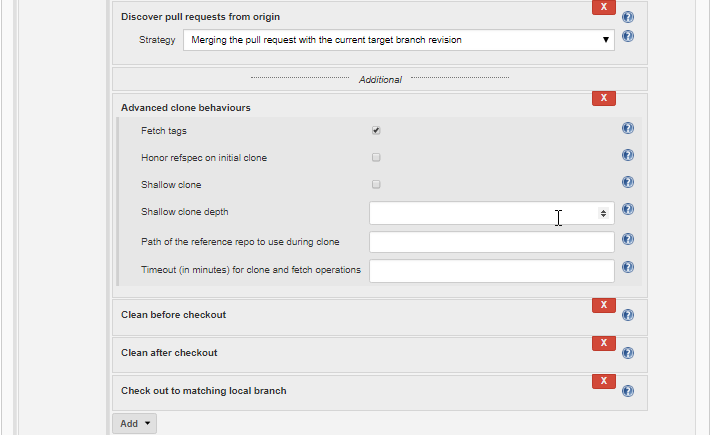
Fortunately, there are two good tools out there, which have come about thanks to folks who do the builds for Fedora. The first of these is mock, which comes straight from the team maintaining tools such as rpm, createrepo, yum, dnf, and other goodies. That team includes several folks from Red Hat, and at least one from SUSE, both vendors using the RPM package format for distributing their software. The mock tool focuses almost entirely on the rpmbuild step, and the setup surrounding it. That may not seem like much at first, but when you look at what it takes to setup the build environment (create a chroot environment, install all the things needed to do the build into the chroot, making sure everything is updated in that environment, and perhaps checking out the source code and building the source archives used by the rpmbuild command), having such a tool for that alone is a blessing. And with all of that, the hardware permitting, just minor changes in the command line can have me building packages for a different OS release (e.g. RHEL 6 instead of RHEL 7, the upcoming Fedora release, or openSUSE), or a different processor (e.g. the i386 instead of the x86_64). It looks like it will even support true cross-compiles such as for the ARM or PPC processors done on the x86_64 host… but I have not tried that. (I used to do something similar with NetBSD, building binary distributions for the Sun 3, HP 700 and PPC processors on a box with the Athlon 2500+ CPU, and this is how we also built the firmware for PPC based network switches at a former employer). So that simplifies the rpmbuild step, but does not handle the other steps, particularly if I want to have everything 100% automated, such as by a job which runs in Jenkins any time I do a code commit (such as deciding I am going to have a new persistent virtual host for a new web server). For that, we have tito.
The author of tito is another individual at Red Hat, Devan Goodwin, and his work takes some of the other tasks in that blue box I labeled “Build”, and pulls them all together, with some additional niceties. These include handling tagging releases in git, doing the copying and doing the publishing steps associated with a release for a number of different build/release platforms such as copr/koji, or directly to Yum repositories maintained via rsync, and even producing initial builds and and RPMs. There are some things I would definitely have done differently, but such is always the case… no matter how much we talk about how Great minds think alike
, it does not always work out that way… at best, there is a synergy which forms, allowing something better than the individuals would produce by themselves to result from their working together. As a result, I have forked his project (one of the great things about Open Source) to make a few changes which are definitely being fed back to him, primarily starting with local Yum repositories (no need to rsync if you can avoid it, and there are times you definitely do not want to do so), and depending on the response I get on some other items, some of my other ideas will either go forward in my own version, or get pulled into the master project. As I had driven home while working at Bell Labs on a project which was aiming for TL9001 after years of working under ISO 9001, there is always room for improvement.
What else is there?
There are two really big goals once I finish up the initial coding for the enhancement for local Yum repositories. These deal with what is called Continuous Integration/Continuous Deployment (CI/CD), and are:
- Automatic builds within Jenkins triggered by commits to both my forked project, but also using the same for other projects. (e.g. “Dogfood” my own work, otherwise, why would I have done it??)
- Doing the builds within docker containers, which are yet another step up from the chroot environment of mock.
- Build success notification.
- Upstream repository merges into my forked repository, with automatic integration testing.
Following the theme… I want a lawnmower the size of a combine, which handles all the things I would normally do for these tasks, without me even having to drive… (and of course, powered by solar, wind or a Mr. Fusion eventually as well. 🙂 )
A bit of an afterword here… This is my first post using WP 5.0 and the new Gutenberg editor… While there are some things which are nice about it, there are others which I find frustrating. Probably the biggest one of this post is the difficulties surrounding inline formatting. While I have the “buttons” up top for bold (<b></b>), italic (<i></i>), and strikethrough (<del></del>), the lack of equivalents for me to ease the use of code (<code></code>), keyboard (<kbd></kdb>), sample output (<samp></samp>) and variables (<var></var>), along with short quotes (<q></q>) is frustrating. Nor does it look like they are there, just waiting for me to learn the key sequences. But hey… WordPress is Open Source, and so… 🙂